
Keep your LLM powered
application ahead of constantly
changing data
To keep responses accurate, LLMs need access to up to date data. Indexify extracts continuously in near real-time (< 5ms) to ensure the data your LLM application depends on is current, without you needing to think about CRON jobs or reactivity.


Extract from video,
audio, and PDFs
Indexify is multi-modal and comes with pre-built extractors for unstructured data, complete with state of the art embedding and chunking. You can create your own custom extractors using the Indexify SDK, too.
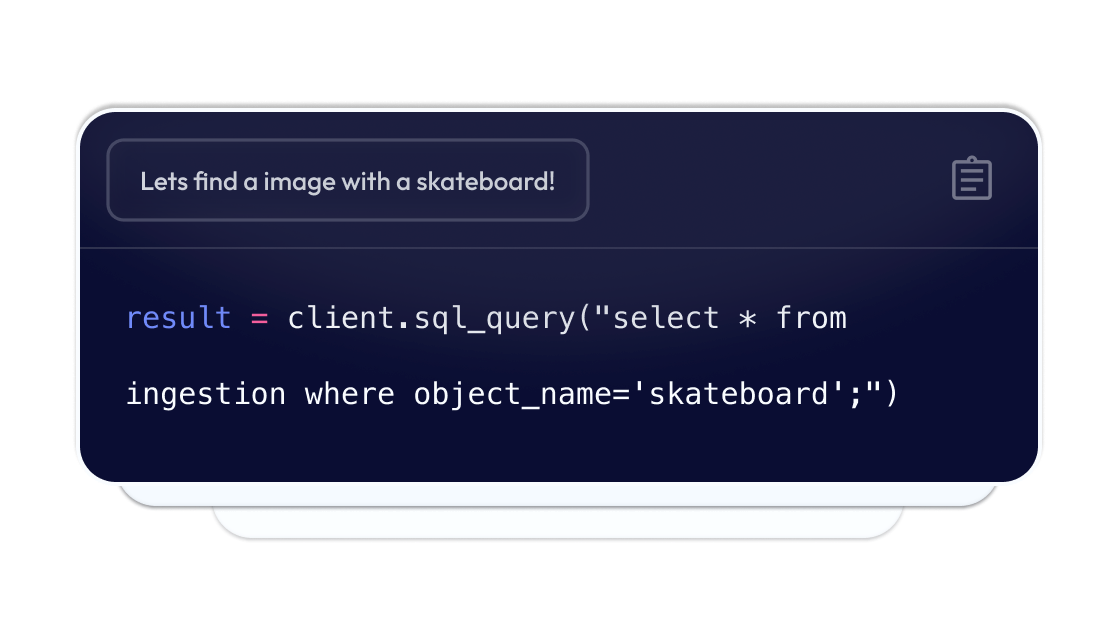
Query using SQL and
semantic search
Just because your data is unstructured doesn't mean it needs to be difficult to retrieve. Indexify supports querying images, videos, and PDFs with semantic search and even SQL, so your LLMs can get the most accurate, up to date data for every response.
From prototype to
production
Indexify runs just as smoothly on your laptop as it does across 1000s of autoscaling nodes.
Start prototyping with Indexify’s local runtime and when you are ready for production, take advantage of our pre-configured deployment templates for K8s (or VMs) or even bare metal. Everything is observable out of the box, whether its ingestion speed, extraction load or retrieval latency.
Economics and Availability


Enterprise Grade Tooling for
Ambitious Startups
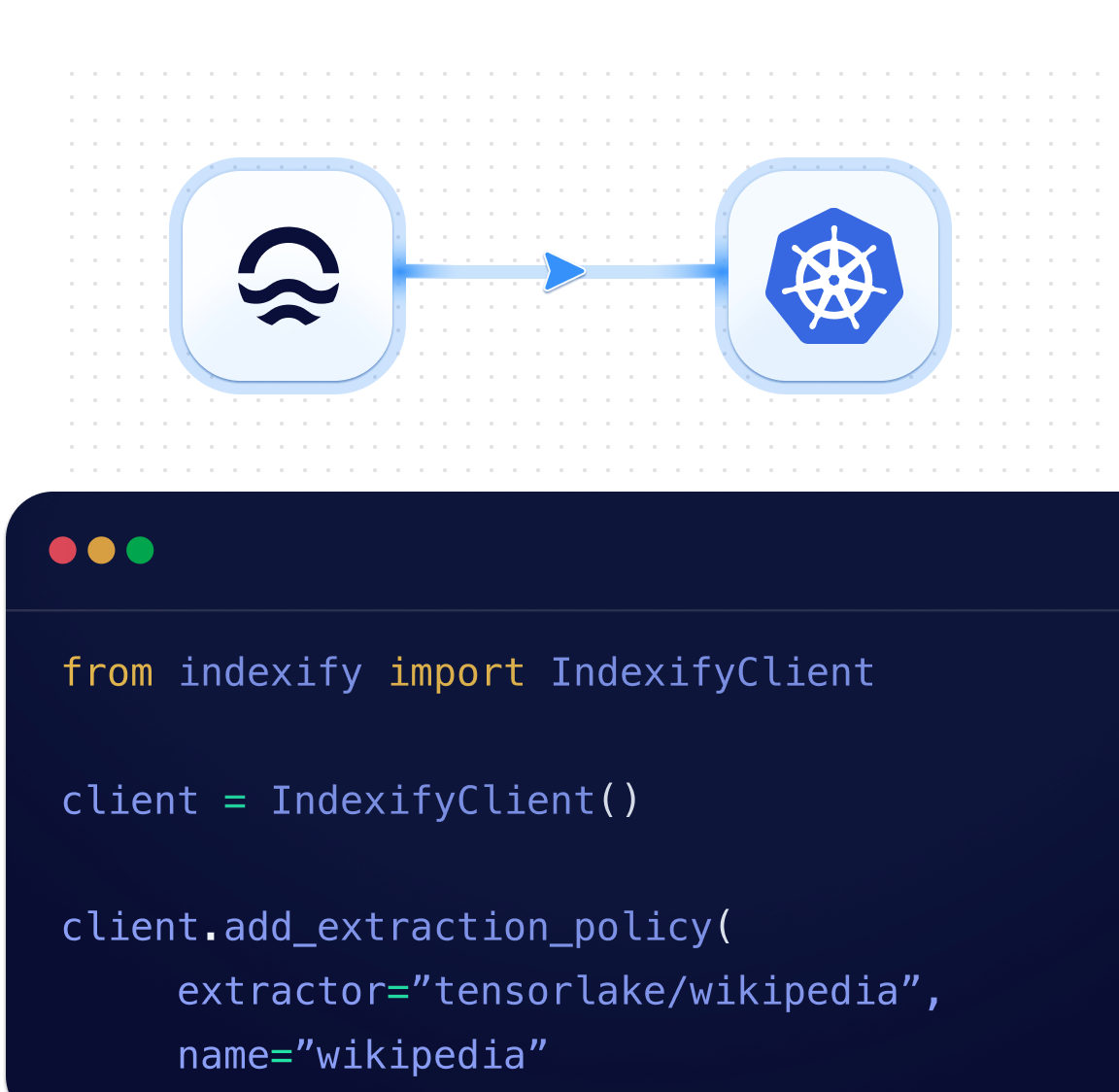
Ready to Use Deploy on Kubernetes
Indexify can be deployed on Kubernetes. It can autoscale and handle any amount of data.
End to End Observability and Monitoring
The retrieval and extraction systems are instrumented. Know bottlenecks and optimize retrieval and extraction.
Integrate With Vector Databases & LLM
Works with existing LLM applications and vector databases. No need to change your existing infrastructure.